The key to scalability is to know where your bottlenecks are. And the only way to know them is by instrumenting your code.
Vitaliy Mogilevskiy December 15, 2010
Posted In: Operations
The key to scalability is to know where your bottlenecks are. And the only way to know them is by instrumenting your code.
Vitaliy Mogilevskiy December 15, 2010
Posted In: Operations
As you probably know by now, Oracle retired perfectly fine Classic Metalink for the Flash based “My Oracle Support“. How do you like it so far? Have you been getting the dreaded errors such as “A server connection error occurred. You cannot continue Please try again later.”:

Vitaliy Mogilevskiy November 10, 2009
Posted In: Operations
Tags: Metalink, My Oracle Support
Wow, that’s a handful — “restore which I didn’t do“, alright then why mention it? Well, here’s why. Imagine you get an email with a title “PROJECT-NAME – QA Schema Rollback?” You quickly read through it and realize that a developer messed up a very important heavily used schema on a QA system for a project that’s about to go live. A quick analysis of the situation reveals that a delete was issued on three tables setup with “cascade constraints” clause and it wiped out data from 11 detail tables. Why would you do that is another question, which I took up with the development team but I digress …
What do you do?
First thing that came to my mind was “flashback“! Sounds good, but what do you flashback? A schema? No such thing. A table? Maybe, but what about referential integrity in 11 detail tables? That’s OK it can be solved like this — I flashback the master tables first and then the 11 detail tables, it might work … Lets check the pre-reqs — undo_management=AUTO (check), undo_retention = 900 (not good — it’s been over 15 minutes). Alright, forget about flashing back anything (mental note to myself — increase undo_retention to few hours).
What’s next?
The next thing is point in time recovery. Quick check shows that the schema is fully contained in a single tablespace — very good, we can do a tablespace level recovery instead of the whole database. And since we are on 10gR2 how about fully automated RMAN TSPITR? Sounds good, lets see what we need for this to work:
- The target instance, containing the tablespace to be recovered
- The Recovery Manager client
- The control file and (optional) recovery catalog, used for the RMAN repository records of backup activity
- Archived redo logs and backup sets from the target database, which are the source of the reconstructed tablespace.
- The auxiliary instance, an Oracle database instance used in the recovery process to perform the actual work of recovery.
- The target time, the point in time or SCN that the tablespace will be left at after TSPITR
- The recovery set, which consists of the datafiles containing the tablespaces to be recovered;
- The auxiliary set, which includes datafiles required for TSPITR of the recovery set which are not themselves part of the recovery set. The auxiliary set typically includes:
- The auxiliary destination, an optional location on disk which can be used to store any of the auxiliary set datafiles, control files and online logs of the auxiliary instance during TSPITR. Files stored here can be deleted after TSPITR is complete.
A handful list, but doable. Alright, suppose I have all this (I did) and suppose I want to go through it, how does it work? Here’s how:
To perform TSPITR of the recovery set using RMAN and an automated auxiliary instance, you carry out the preparations for TSPITR described in “Planning and Preparing for TSPITR”, and then issue the RECOVER TABLESPACE command, specifying, at a minimum, the tablespaces of the recovery set and the target time for the point-in-time recovery, and, if desired, an auxiliary destination as well. RMAN then carries out the following steps:
- If there is no connection to an auxiliary instance, RMAN creates the auxiliary instance, starts it up and connects to it.
- Takes the tablespaces to be recovered offline in the target database
- Restores a backup control file from a point in time before the target time to the auxiliary instance
- Restores the datafiles from the recovery set and the auxiliary set to the auxiliary instance. Files are restored either in locations you specify for each file, or the original location of the file (for recovery set files) or in the auxiliary destination (for auxiliary set files, if you used the AUXILIARY DESTINATION argument of RECOVER TABLESPACE)
- Recovers the restored datafiles in the auxiliary instance to the specified time
- Opens the auxiliary database with the RESETLOGS option
- Exports the dictionary metadata about objects in the recovered tablespaces to the target database
- Shuts down the auxiliary instance
- Issues SWITCH commands on the target instance, so that the target database control file now points to the datafiles in the recovery set that were just recovered at the auxiliary instance.
- Imports the dictionary metadata from the auxiliary instance to the target instance, allowing the recovered objects to be accessed.
- Deletes all auxiliary set files.
At that point the TSPITR process is complete. The recovery set datafiles are returned to their contents at the specified point in time, and belong to the target database.
The first thing that should jump at you here is item# 2 — “Takes the tablespaces to be recovered offline in the target database” because that’s when the real downtime will begin. Why? Because realize that while some of the schema’s data might have been lost, at least in this particular case it’s not caused a compete outage yet, we still have a website connected to it and functioning. But as soon as I take the tablespace offline it will be a true outage and I will be under the gun to deliver it ASAP. ASAP == interruptions and stress, which as you know inevitably leads to mistakes. And mistakes made while performing RMAN’s TSPITR could cause quite serious issues, much bigger then you’ve started with.
Here’s one scenario where it’s very easy to make a mistake. Lest say the developer tells you that the schema was corrupted at t1. You go through with RMAN TSPITR and realize that he was wrong and that you need to redo RMAN TSPITR using t1-15 minutes. Can you do that? ………. The answer is Not unless you are using recovery catalog, here’s why:
Assume that you run TSPITR on a tablespace, and then bring the tablespace online at time t. Backups of the tablespace created before time t are no longer usable for recovery with a current control file. You cannot run TSPITR again on this tablespace to recover it to any time less than or equal to time t, nor can you use the current control file to recover the database to any time less than or equal to t. Therefore, you must back up the recovered tablespace as soon as TSPITR is complete.
It is extremely important that you choose the right target time or SCN for your TSPITR. As noted already, once you bring a tablespace online after TSPITR, you cannot use any backup from a time earlier than the moment you brought the tablespace online. In practice, this means that you cannot make a second attempt at TSPITR if you choose the wrong target time the first time, unless you are using a recovery catalog. (If you have a recovery catalog, however, you can perform repeated TSPITRs to different target times.)
For example, assume that you are not using a recovery catalog, and you run TSPITR on a tablespace, and then bring the tablespace online at 5PM on Friday. Backups of the tablespace created before 5PM Friday are no longer usable for recovery with a current control file. You cannot run TSPITR again on this tablespace with a target time earlier than 5PM Friday, nor can you use the current control file to recover the database to any time earlier than 5PM Friday. Your only option will be point-in-time recovery of your entire database using a restored control file.
Now that’s a bit of a problem isn’t it? What this means is that you might actually have just ONE SHOOT at getting it right. You miss it and you might be done, at least with using RMAN TSPITR, you can still recover full database using backup control file from before time t.
Considering all of these nuances it quickly became apparent to me that perhaps RMAN TSPITR is not the right solution in this case. It sure sounded great on paper. What’s not to like here, just one command like this:
RECOVER TABLESPACE users, tools
UNTIL LOGSEQ 1300 THREAD 1
AUXILIARY DESTINATION '/disk1/auxdest';
Solves your issue! But it’s not as simple, it’s not just one command, there’s a lot more to this and even if you are willing to take the risk there are other limitations you need to be aware of. If any of the following exists in the tablespace to be recovered, then RMAN TSPITR will not work:
You’d know if you had any Snapshot logs or tables because DBA’s typically set those up, the same thing applies to RBS/UNDO/SYS objects. Checking the rest would be easy:
SQL> col data_type format a30
SQL> r
1 select count(*),DATA_TYPE from dba_tab_columns where owner='SCHEMA-IN-TABLESPACE'
2* group by DATA_TYPE
COUNT(*) DATA_TYPE
---------- ------------------------------
2 LONG RAW
72 NUMBER
1 CLOB
20 DATE
200 VARCHAR2
2 BLOB
6 rows selected.
SQL> select count(*) from dba_nested_tables where owner='SCHEMA-IN-TABLESPACE'
2 ;
COUNT(*)
----------
0
SQL> select count(*) from dba_external_tables where owner='SCHEMA-IN-TABLESPACE'
2 ;
COUNT(*)
----------
0
SQL>
You also have to consider that all the while you are thinking and researching, the database is still being accessed, and it’s entirely possible that changes are being made to the schema in question. If you restore it to the time in the past all of these changes will lost, so you’d have to actually take a quick backup of the schema as it is now before you perform RMAN TSPITR just in case you’ll need anything from it …
Also realize that all of this information you have to either know my heart or sift through very quickly because a decision needs to be made as to how to solve this issue. And unless you have recently practiced RMAN TSPITR on this specific tablespace in this specific database a conservative DBA, which all DBAs should be, would never make a decision to use RMAN TSPITR. I didn’t — I used RMAN backup set to recover the database on another host, exported the schema in question and imported it as another schema into the original database so that developers could reconstruct lost rows from it. My solution, while not the fastest was the sure thing and that’s what our job is all about.
Vitaliy Mogilevskiy October 7, 2009
Posted In: Operations, RMAN
Tags: RMAN, RMAN TSPITR
You are probably wondering what is EVNT?
EVNT is an Oracle monitoring framework I wrote and have been using since 2002. My then boss encouraged me to devote few months of my time to automating all our monitoring needs. We analyzed our requirements, designed the framework and I wrote all the code in few months. In retrospect, this was the best time investment we’ve made — it’s still serving us well after all these years and numerous upgrades — we started with 8.1.7 and now are on 10gR2. Which brings me to why I started this post — I just wrote up EVNT install notes for 10.2.0.4.
I also heavily use OEM — it’s good for lots of things and not so good for others. Ironically, I still don’t trust OEM for critical database up-time monitoring. And if you too, feel that OEM is missing in some areas I encourage you to give EVNT a shoot — DOWNLOAD: EVNT – Event Monitoring Framework for Oracle. EVNT is especially useful to those DBAs that rely heavily on sqlplus/shell scripts for database monitoring.
Vitaliy Mogilevskiy September 30, 2009
Posted In: Operations
Tags: EVNT, monitoring framework
It took Oracle buying SUN to finally come out with something worthy this relationship — Exadata Version 2. Oracle has killed two birds with one stone capitalizing on their superior Oracle Enterprise Linux and SUN’s x64 hardware, once again proving that it’s bet is on OEL not Solaris.
The pricing model allows incremental growth using the following stages:
Basic System – $110,000
Quarter Rack – $350,000
Half Rack – $650,000
Full Rack – $1.15M

Key Internals are as follows (per Full RACK):
8 Sun Fire X4170 DB Nodes per RACK
14 Sun Fire X4275 Storage Nodes per RACK
Combo of multiple Sun Quad Data Rate (QDR) Datacenter InfiniBand Switches 36 capable of 40Gb/sec
Oracle/SUN claim that by using X4275 they were able to significantly simplify storage solution eliminating complex SAN architectures. Here’s a brief overview of the architecture – Sun Oracle Database Machine and Exadata Storage Server. And here’s the presentation Larry Ellison gave at The Sun Oracle Database Machine Announcement.
So is Exadata Version 2 a final blow to Oracle/HP relationship? Time will tell, all I can say is that we couldn’t be happier with our HP hardware running Oracle Application Servers, Oracle RAC and various middle-tier solutions on Oracle EL.
Vitaliy Mogilevskiy September 22, 2009
Posted In: Operations
Tags: Exadata Version 2, InfiniBand, Linux, solaris, SUN, X4170, X4275
I was just applying PSU 8576156 on a 10.2.0.4 installation under Solaris and I was surprised to learn that it requires you to provide your metalink username/email address and optionally password, under disguise of “to be informed of security issues“. Once you provide your email/password it immediately tries to validate the information by contacting oracle’s servers via HTTP — it doesn’t bother to check if you have a proxy it just goes out there and hangs for few minutes eventually failing to connect at which point you are asked if there’s an HTTP PROXY on your network. Only after failing to connect, you are finally given a chance to OPT-Out of this ridiculous practice of information gathering by specifying “NONE” in the “Proxy specification“:
box.SID-> /u01/app/oracle/product/10.2.0/db_1/OPatch/opatch apply
Invoking OPatch 10.2.0.4.7
Oracle Interim Patch Installer version 10.2.0.4.7
Copyright (c) 2009, Oracle Corporation. All rights reserved.
Oracle Home : /u01/app/oracle/product/10.2.0/db_1
Central Inventory : /u01/app/oracle/oraInventory
from : /var/opt/oracle/oraInst.loc
OPatch version : 10.2.0.4.7
OUI version : 10.2.0.4.0
OUI location : /u01/app/oracle/product/10.2.0/db_1/oui
Log file location : /u01/app/oracle/product/10.2.0/db_1/cfgtoollogs/opatch/opatch2009-09-21_17-12-50PM.log
Patch history file: /u01/app/oracle/product/10.2.0/db_1/cfgtoollogs/opatch/opatch_history.txt
ApplySession applying interim patch '8576156' to OH '/u01/app/oracle/product/10.2.0/db_1'
Running prerequisite checks...
Provide your email address to be informed of security issues, install and
initiate Oracle Configuration Manager. Easier for you if you use your My
Oracle Support Email address/User Name.
Visit http://www.oracle.com/support/policies.html for details.
Email address/User Name: your.metalink-email@your-company.com
Password (optional):
Unable to establish a network connection to Oracle. If your systems require a
proxy server for outbound Internet connections, enter the proxy server details
in this format:
[@][:]
If you want to remain uninformed of critical security issues in your
configuration, enter NONE
Proxy specification: NONE
Enjoy the all new Patch Set Update!
Vitaliy Mogilevskiy September 21, 2009
Posted In: Operations
Tags: Oracle PSU, Patch Set Update, PSU 8576156
I don’t normally use vncserver, I prefer SSH X11 tunneling/forwarding due to it’s inherited security, but sometimes there have been issues with X11/SSH and it’s nice to know an alternative. This quick how-to is meant for an Oracle DBA looking for a quick way to run GUI tools from the Oracle stack, such as runInstaller, dbca, dbua, etc.. It is not meant to serve as a step by step guide to setup a secure, reusable vncserver setup in your environment, I do however provide some additional references where you can find additional information (see the end of this post).
Lets get to it then — the good news is that vncserver should already be installed on your RHEL / OEL. All you have to do is start it up and tell it the display number like so:
[root@rac1 ~]# su - oracle
rac1.XRACP1-> vncserver :12
You will require a password to access your desktops.
Password:
Verify:
New 'rac1.mydomain.com:12 (oracle)' desktop is rac1.mydomain.com:12
Creating default startup script /u01/app/oracle/.vnc/xstartup
Starting applications specified in /u01/app/oracle/.vnc/xstartup
Log file is/u01/app/oracle/.vnc/rac1.mydomain.com:12.log
rac1.XRACP1-> ps -ef | grep vnc
oracle 31123 1 0 13:04 pts/1 00:00:00 Xvnc :12 -desktop rac1.mydomain.com:12 (oracle) -httpd /usr/share/vnc/classes -auth /u01/app/oracle/.Xauthority -geometry 1024x768 -depth 16 -rfbwait 30000 -rfbauth /u01/app/oracle/.vnc/passwd -rfbport 5912 -pn
oracle 31158 1 0 13:04 pts/1 00:00:00 vncconfig -iconic
oracle 32309 31078 0 13:05 pts/1 00:00:00 grep vnc
rac1.XRACP1->
If you want to kill vncserver use “vncserver -kill :12” command where :12 is the display number you specified when starting it:
vncserver -kill :12
rac1.XRACP1-> ps -ef | grep vnc
oracle 9597 1 1 17:50 pts/3 00:00:00 Xvnc :12 -desktop rac1.mydomain.com:12 (oracle) -httpd /usr/share/vnc/classes -auth /u01/app/oracle/.Xauthority -geometry 1024x768 -depth 16 -rfbwait 30000 -rfbauth /u01/app/oracle/.vnc/passwd -rfbport 5912 -pn
oracle 10065 1 0 17:50 pts/3 00:00:00 vncconfig -iconic
oracle 10303 9514 0 17:50 pts/3 00:00:00 grep vnc
rac1.XRACP1-> vncserver -kill :12
Killing Xvnc process ID 9597
rac1.XRACP1-> ps -ef | grep vnc
oracle 14396 9514 0 17:52 pts/3 00:00:00 grep vnc
rac1.XRACP1->
That’s all to it, next you can access the display via http://host:58XX where XX is the screen number you specified when starting the vncserver:
http://rac1.mydomain.com:5812
REFERENCE:
Note: 551711.1 Linux OS Service ‘vncserver’
Note: 735767.1 How to Setup VNC Server with Clipboard Support on RHEL/OEL
APRESS Book: Linux Recipes for Oracle DBAs
Vitaliy Mogilevskiy September 16, 2009
Posted In: Linux, Operations
Tags: vncserver
Sometimes basic things like installing the latest Oracle instantclient on the PCs of all of your developers can take considerable time. I typically setup a dedicated DBA Portal website wherever I work and then write up instructions for repetitive things like these. It’s all about – do it once and forget it. Here’s the copy of the writeup I did to install the latest 11g Oracle instantclient basic and instantclient sqlplus on win32:
Go to Instant Client Downloads for Microsoft Windows (32-bit) download page:
http://www.oracle.com/technology/software/tech/oci/instantclient/htdocs/winsoft.html
And download basic-win32 and sqlplus-win32 files to your PC (for example):
Create a C:\oracle directory on your C drive (if you don’t already have one) and move both files into C:\oracle.
instantclient-basic-win32-11.1.0.7.0.zipinstantclient-sqlplus-win32-11.1.0.7.0.zipto unzip:
End result should be a new folder called instantclient_11_1 in your C:\oracle:


In the System Variables panel select Path variable and click Edit button:
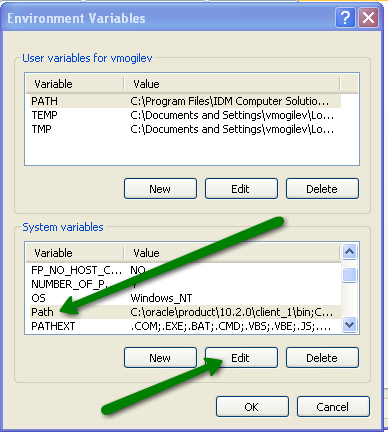
In the Variable Value field paste the following: C:\oracle\instantclient_11_1. Make sure it’s before all other path values that point to your OLD Oracle clients, then clickOk

Now find a variable called TNS_ADMIN – it could be in either panel (System / User), if you don’t have such variable, create it in the User panel by clicking New:
Variable Name: TNS_ADMIN
Variable Value: C:\oracle\instantclient_11_1
Click Ok

If you already have an existing copy of tnsnames.ora file then place it to:
C:\oracle\instantclient_11_1
If you don’t – then create a new tnsnames.ora file, for example:
XRACQ_MYSERVICE_TAF =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = vip-qarac1)(PORT = 1521))
(ADDRESS = (PROTOCOL = TCP)(HOST = vip-qarac2)(PORT = 1521))
(ADDRESS = (PROTOCOL = TCP)(HOST = vip-qarac4)(PORT = 1521))
(ADDRESS = (PROTOCOL = TCP)(HOST = vip-qarac3)(PORT = 1521))
(LOAD_BALANCE = yes)
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = XRACQ_MYSERVICE_TAF.domain.com)
(FAILOVER_MODE =
(TYPE = SELECT)
(METHOD = BASIC)
(RETRIES = 180)
(DELAY = 5)
)
)
)

in the CMD window’s prompt – enter the following: sqlplus user/pass@TNS_ALIAS where:
user: is the database username given to you by the DBA
pass: is the database password given to you by the DBA
TNS_ALIAS: The alias you setup in the tnsnames.ora file
example:
C:\>sqlplus xxx/xxxxxxxx@XRACQ_MYSERVICE_TAF
SQL*Plus: Release 11.1.0.7.0 - Production on Wed Aug 26 16:24:23 2009
Copyright (c) 1982, 2008, Oracle. All rights reserved.
Connected to:
Oracle Database 10g Enterprise Edition Release 10.2.0.4.0 - 64bit Production
With the Partitioning, Real Application Clusters, OLAP, Data Mining
and Real Application Testing options
SQL>
If you get the ORA-12705 error while running sqlplus:
C:\>sqlplus xxxxxx/xxxxxxxx@xxxxxxxxxxx
SQL*Plus: Release 11.1.0.7.0 - Production on Wed Aug 26 16:58:33 2009
Copyright (c) 1982, 2008, Oracle. All rights reserved.
ERROR:
ORA-12705: Cannot access NLS data files or invalid environment specified
Enter user-name:
Here’s the solution:
To fix the ORA-12705: Cannot access NLS data files or invalid environment specified error, go to your registry editor (run regedit from Start->Run) and then:
\HKEY_LOCAL_MACHINE\SOFTWARE\ORACLENLS_LANG from there (select it and delete)Re-run the sqlplus test to make sure it works (you will need to open a new CMD window for the registry changes to take place).
If you’d like to get a copy of this article in an easy to share PDF – please sign up for my newsletter – Confessions of an Oracle DBA where I share tips, scripts and tricks I’ve learned during almost two decades in the tech field as an Oracle DBA:
SUBSCRIBEEnd.
Vitaliy Mogilevskiy August 26, 2009
Posted In: Operations
Tags: instantclient basic, instantclient sqlplus, oracle instant client, win32
It’s been a while since my last post … but this issue I ran into last night is worth mentioning. Here’s what happened — one of my RMAN backups failed with:
RMAN-00571: ===========================================================
RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS ===============
RMAN-00571: ===========================================================
RMAN-03002: failure of backup plus archivelog command at 05/05/2009 23:16:15
ORA-19566: exceeded limit of 0 corrupt blocks for file /u01/app/czgddata/a_txn_data02.dbf
The corrupt block was being reported as part of a segment — a table:
SQL> connect / as sysdba
Connected.
SQL>
SQL>
SQL> select owner, segment_name, segment_type
from dba_extents
where file_id = 401
and 257532 between block_id and block_id + blocks - 1;
2 3 4
OWNER
------------------------------
SEGMENT_NAME
--------------------------------------------------------------------------------
SEGMENT_TYPE
------------------
CZ
CZ_DEVL_PROJECTS
TABLE
But the data was still readable and I was able to move the table to “map the corrupt block” outside of the segment boundaries:
SQL> alter table CZ.CZ_DEVL_PROJECTS move;
Table altered.
SQL> select count(*) from CZ.CZ_DEVL_PROJECTS;
COUNT(*)
----------
312
Still, even after the move the block was still reported corrupt by the dbv and I had to deploy a procedure from the ML-Note: 336133.1. Which I fully documented in here –> How to Format Corrupted Block Not Part of Any Segment.
Vitaliy Mogilevskiy May 6, 2009
Posted In: Operations
Tags: corruption, ORA-19566, RMAN
You’ve been there haven’t you? You buy a product, use it, have an issue, cringe and call support. What comes next either breaks or makes your future relations with the company and the product they sold you. It’s at this point that you find out if they are your partner or you are on your own. With consumer products my expectation for a good one is to never break — I don’t ever want to have to call their support. But when it comes to the toys we use in data centers I want to hit all of the big issues during QA and I want it to break down so badly that it will stump the technical support team so we get a chance to test their infrastructure and protocols.
That’s exactly what happened to one of the key products we selected for our latest large scale implementation. It’s irrelevant to this article what that product is, what’s relevant is that the support organization experience was disappointing. I am not going to focus on what went wrong — it really isn’t that important, what’s important is that we got the message across and it appears we’ll have a meeting with the people that might be able to make a difference. And I really hope that they do — I believe this company has potential.
I was thinking about the upcoming meeting and what to address and here’s what I realized. It’s actually very simple — here’s my list of things I Need From a Support Organization of a technology company:
Community is where you go first if you have a non urgent question. Community needs to consist of three components:
Knowledge Base needs to offer an up to date list of known issues and white papers that bridge the gap between official documentation and what customers are actually going through while doing hands on implementations. Bug Database is where you get a chance to feel the pulse of the company — it’s an integral part of the community and it doesn’t have to be an open Bug database that we see in the open source communities, no, just a read-only access where you get to see what kinds of issues development is working on these days. Through Forums you share experiences with other customers and learn best practices by picking the brains of the community gurus. Forums is what connects you with the rest of the customer base and gives you a chance to see the bigger picture, it also shows that the company is open about it’s business and is not afraid of public scrutiny.
Communication is one of the most critical aspects of a support organization. It needs to flow both ways — customer to support and support to the customer. Support needs to drive Communication, they need to deliver instant updates to your issue and they need to squeeze the last drop of information from you because even the smallest piece of information can play a huge role in how effective a solution will be or how it will help other customers that might be facing similar symptoms but have not yet identified the cause of the problem. Communication is the only thing that allows a good support organization to create strong Knowledge Base because it’s the only way to gage what you are really experiencing in the field.
For example a failure of their product might have an adverse affect on other products within your technology stack so it’s imperative for support to ask you for the error messages that you might have seen with the rest of the components so that these symptoms can be properly documented and published in the knowledge base as a white paper or an alert.
Response is the most critical aspect of the support organization. The worst thing you as a customer can experience is when your requests are being ignored or lost in the queue. You need to know as soon as possible that someone is looking into the issue and it better NOT be an boilerplate response from an automated system. Response needs to include action plan — it’s not enough to simply say “We are working on it” — it should provide an action plan even if it involves you — the customer. Response goes hand in hand with communication and it needs to be recorded into a system that you can login to view history of events. Just like Communication, Response goes both ways and support needs to drive it — if a customer is delaying response to a request for information support needs to follow up immediately.
And there you have it — Community, Communication, Response = effective support organization.
Vitaliy Mogilevskiy August 14, 2008
Posted In: Operations
Tags: support